Video
Project Summary
Our project is a Super Mario Maker™ gameplay simulation in Minecraft, including two pieces of mechanism: a Mario player and a world map generator.
The generator gives random world arrangements like world levels of Super Mario Bros, which are environments that the mario agent interacts with.
The goal for the agent is to reach the end of the level without falling into pits or hitting with enemies. And the agent interacts with the environment like human players do. It sees a part of the world map around it and decides an action to take. Therefore, the agent is a partially observable agent. Specifically, at each time step, it perceives a stack (5) of recent visible frames from the environment that surrounds it and makes a decision for the next action. The overview of the agent input/output is shown below:
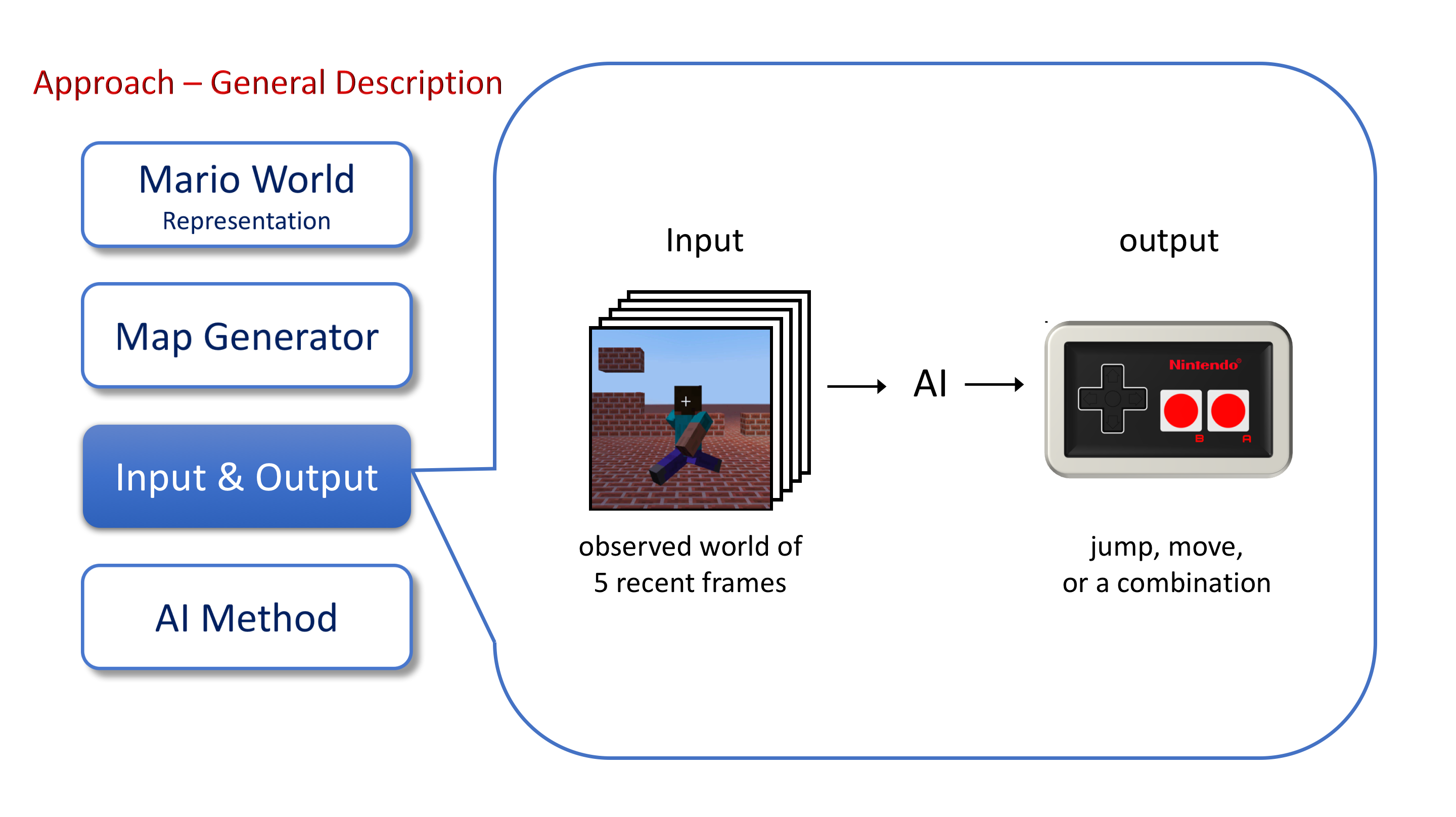
Playing mario with computational algorithms has been an interesting idea for decades, since it is a similar problem to robot maneuvering problems and path-planning problems, which have great significance in real life and are hard to solve with traditional algorithms. Previous methods include a-star and multilayer-perceptrons. However, they either require global map information and manual heuristic design(A*) or lack strong spatial inference capacities. Recent advances in combining reinforcement learning and convolutional neural networks have enabled the method of building an end-to-end neural network with such capacities. Therefore, our project is an end-to-end neural network based AI system to solve the mario playing problem.
Approaches
Part I: Environment setup and World Representations
-
World representations: Since the environment is built on Minecraft, common objects in super mario world are represented by similar objects in Minecraft:
- Minecraft Bricks: Ground, ceilings, pipes, anything you cannot bread in super mario world. unbreakable brick in Super Mario Bro.
- Minecraft Lava: Enemies, pits, anything that kills mario.
- Minecraft Mushroom: Goal Flags.
-
Environment Rules: Simple rules that the mario world run on.
- Movement: Like any simple objects in real life, the movement of mario is determined by displacement, velocity, and acceleration.
- Interaction: Mario is not ghost and cannot go through walls or enemies. If he hits into a wall, he will stop; if he hits into an enemy, he will die.
- Implementation: Implementation details are covered in the physics simulation section of appendix.
-
Agent Reward: Reward function for both the reinforcement learning and A* heuristics
- Definition: $Reward(state) = 3000 - \lVert P_{destination} - P_{state} \rVert_1 \text{(L1 distance)}$, where 3000 is a rough estimation of expected path length.
Part II: Baseline Method
-
A*: A* agent is different to the proposed method in terms of the expected input and prior knowledge. Therefore A* to reinforcement learning is not an apple-to-apple comparison. The only reason for using A* as a baseline is to provide some conceptual and qualitative comparisons.
- State space: All possible combinations of mario’s displacement, velocity, and acceleration.
- State transfer: From t to t+1, any states that can be obtained by advancing a time step from the current state without making mario die.
- Heuristic: $h(state) = \lVert P_{destination} - P_{state} \rVert_1$
- Unfairness: A* has both the global world map and exact state transfer functions, while the reinforcement learning agent can only see a small part of the world map around mario and it has no prior knowledge about the state transfer function. To quantitatively compare A* with a such agent does not make sense. However, in the evaluation section, we will show qualitative comparisons, which indicate that A* is computationally intractable due to infinite amount of states in continuous state space.
-
Basic CNN with supervised training:
- Dataset: Generated by manual playing.
- Input/Output: A cropped region of the world map around mario is the input, and output is a probability distribution over several actions. The details of cropping and encoding method is the same as the proposed method and therefore covered in the following section.
- Architecture: Stacking of convolution, batch normalization, activation layers, global average pooling, fully connected layer, softmax.
- Training: Supervised training with adadelta gradient descent.
Part III: Proposed Method
The dataset has pairs of frame-action correspondences. For each pair, a visible frame is cropped and an action is sampled.
-
Map Generation: Before a set of frame-action correspondences is collected, an unique world map is generated for producing the set. Maps are generated from simple obstacles generator or Prim map generator. The simple obstacle generator generates a world with randomly generated blocks and pits patterned like Level 1-1 in Super Mario Bros. The Prim map generator generates a maze-like world with Prim’s algorithm, which is harder to solve due to the requirements of spatial reasoning.
-
Visible Frame Crop: A square region around Mario is cropped as the perception to agents at a particular time.
-
Action Labels: An A-star search with global perception gives a plausible route from the beginning to the end, which consists of a series of actions at each time step. With the one-to-one mapping relationship to time step, action series can be combined with corresponding visible frames to build frame-action pairs.
-
Action Downsampling: With the observation that human players usually cannot change actions at every 60 frames in second, we introduce a prior of action downsampling. During a period of time, agents (including a-star search) can only change its action every 5 frames, and gaps between different actions are filled with “remain” actions. This technic is used throughout the whole system. In current design, frames in the gap are discarded and only frames with action labels are used to build the dataset. However, we are planning on building 5frames-action pairs in later development to give temporal information to advanced agents.
Part IV: Supervised Training

The basic end-to-end neural network modal is a stack of CNN layers + ConvLSTM trained with Q-learning.
-
Input: A visible frame at a particular time is defined as a 15 blocks x 15 blocks region around Mario. Therefore, the frame can be represented as a square grid with one-hot encoding, where each cell has 4 features with values of [0, 1], indicating the presence of obstacles, Mario, coins, and enemies. Since the position of Mario is not necessarily aligned with block boundaries, a sampling scheme is used to provide finer details. In particular, each block is represented by 4 x 4 pixels, and the presence of a bounding box would result the feature of covered pixels to be turned on. And ground truth label from the dataset is encoded as 6 dimensional vector using one-hot encoding, where each dimension represents an action. When an action is labeled, the corresponding feature will be turned on to 1, and other features will be turned off to 0. Since the simple model only considers 1frame-1action mapping, inputs and labels can be represented as .
-
Structure: The overall architecture is composed of two parts: feature extraction and spatial feature map registration.
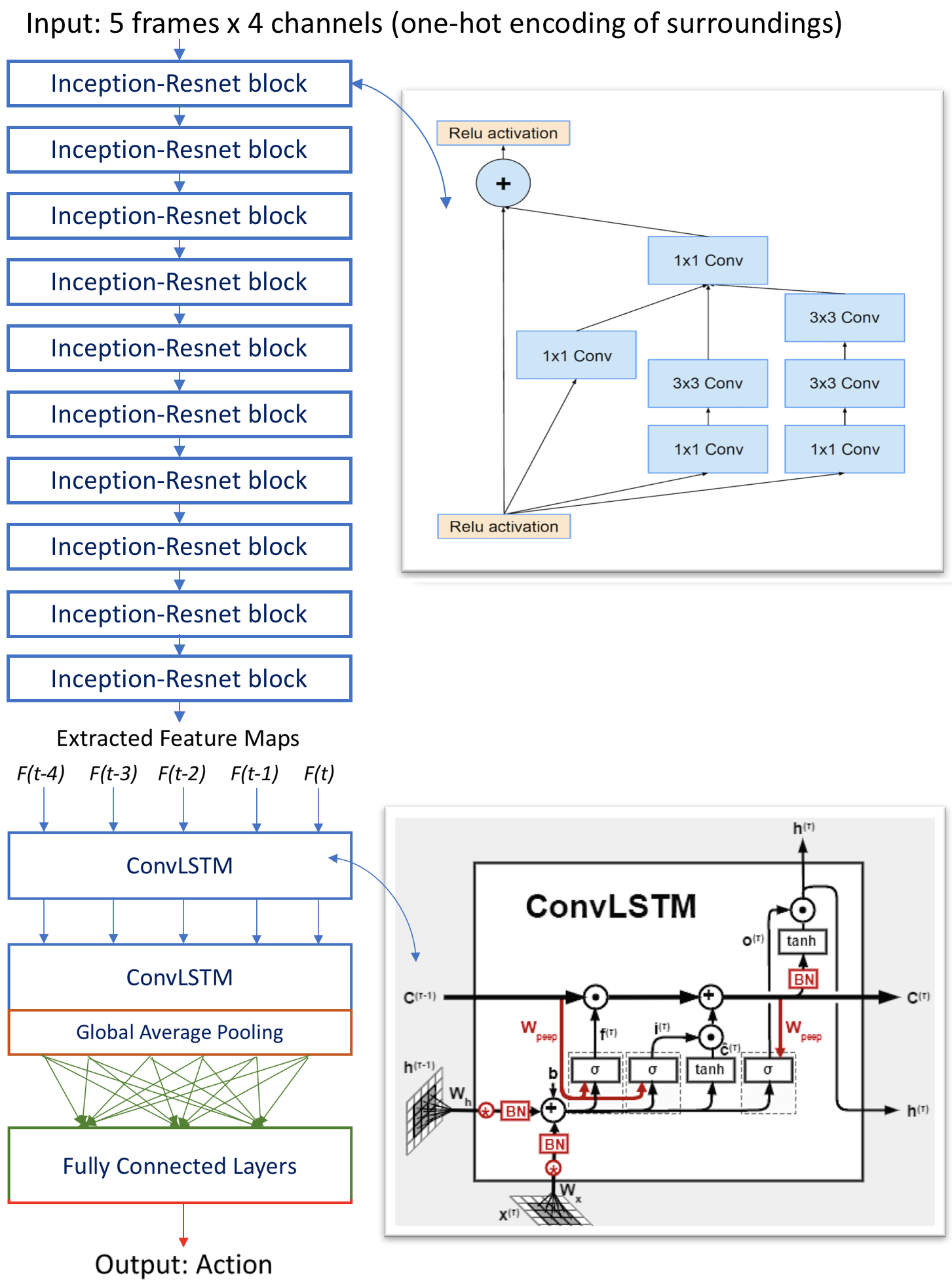 For feature extraction, we use ten inception-resnet blocks to extract the feature maps for object recognition. Those blocks cascade small filters to get larger reception fields with less parameters. The output of this part is five sets of feature maps corresponding to each consecutive frame. For spatial feature map registration, we use two Convolutional LSTM to process these feature maps for object registration, and the result is pooled by a global average pooling layer. Convolutional LSTM is capable of both capturing image information and maintaining long short term memory. Finally, a group of fully connected layers is added to learn the Q-function for Q-learning. The output represents next action of the actor. For design details, please refer to video and our GitHub.
For feature extraction, we use ten inception-resnet blocks to extract the feature maps for object recognition. Those blocks cascade small filters to get larger reception fields with less parameters. The output of this part is five sets of feature maps corresponding to each consecutive frame. For spatial feature map registration, we use two Convolutional LSTM to process these feature maps for object registration, and the result is pooled by a global average pooling layer. Convolutional LSTM is capable of both capturing image information and maintaining long short term memory. Finally, a group of fully connected layers is added to learn the Q-function for Q-learning. The output represents next action of the actor. For design details, please refer to video and our GitHub. -
Training: The model is trained with adam gradient descent optimization to minimize the loss function.
Evaluation
-
A-star: Given enough time, the a star search is able to give a feasible solution. However, it usually takes too long. Thus, we only use a star search to generate examples on small maps to give examples to the neural network model.
-
Neural Network: When trained with the dataset, the prediction accuracy is usually around 80%. Since we have more data points than the parameters in the network, it largely prevents overfitting and the test accuracy is very close to the training accuracy. In randomly generated maps, the success rate of CNN model is around 37%. The most frequent failure is getting stuck in corners.
-
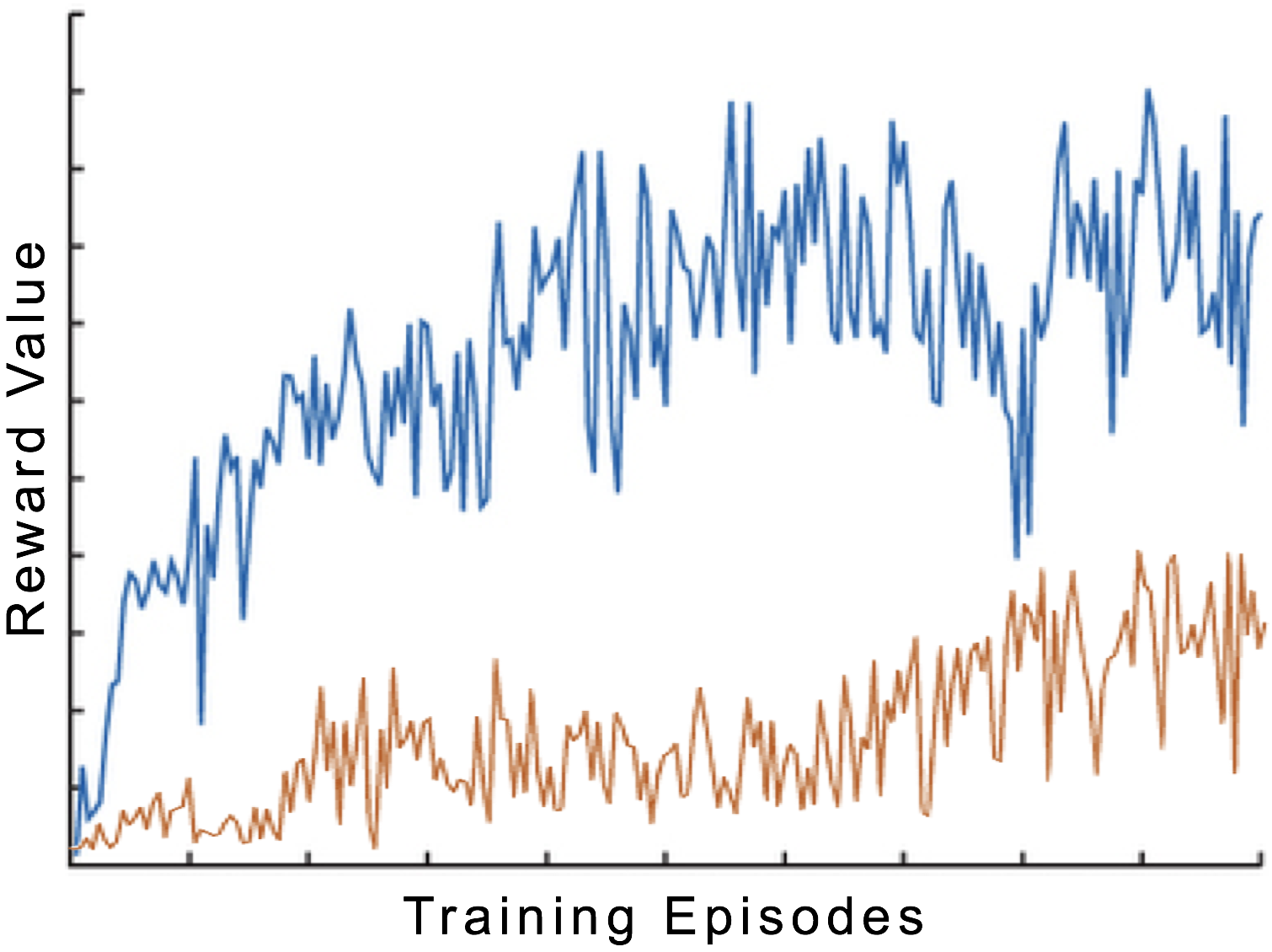
Learning Rate: We compared our new model with status report version. Since we changed to Q-Learning, we now focus on (average) reward value instead of classification accuracy. We can observe that after revising convolutional blocks and adding ConvLSTM for registration, the result improved greatly.
References
[1] Szegedy, C., Ioffe, S., Vanhoucke, V., & Alemi, A. (2016). Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv preprint arXiv:1602.07261.
[2] Ioffe, S., & Szegedy, C. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167.
[3] Xingjian, S. H. I., Chen, Z., Wang, H., Yeung, D. Y., Wong, W. K., & Woo, W. C. (2015). Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Advances in Neural Information Processing Systems (pp. 802-810).
Appendix
-
Physics Engine Implementation: Since Minecraft physics engine has its own rules, we create a separate physics engine in python including Newtonian mechanical dynamics simulation and rigid body collision resolution. Simulation results are sent to Malmo for each frame. One of the core simulation mechanism is a time variant linear system, where a 3 by 3 matrix represents the Newtonian mechanical dynamics of Mario: , where denotes displacement, velocity and acceleration respectively.
- Status Update: For each time step , a matrix multiplication would give the next state by preserving the following equations: , . Parameters of the original SuperMarioBros physics are replicated to reproduce the authentic controlling style of it.
- Actor control: We support a group of actions and action combinations. Like the “LFAB” buttons of original Super Mario Bros game, our control design can make 6 actions: jump, left move, right move, jump with left move, jump with right move, remain. Implementation of actions are achieved by manipulating specific velocity and accelerations of the system.
- Collision: If Mario collide with the ground, y-velocity will be cancelled; if collide up to a brick, y-axis velocity will be inverted; if collide to bricks in sides, x-axis velocity will be cancelled.